论文笔记《NOPE:Novel Object Pose Estimation from a Single Image》

论文笔记《NOPE:Novel Object Pose Estimation from a Single Image》
KarlNOPE: Novel Object Pose Estimation from a Single Image
原文链接:论文笔记《NOPE:Novel Object Pose Estimation from a Single Image》 | Karl的博客
CSDN链接:论文笔记《NOPE: Novel Object Pose Estimation from a Single Image》-CSDN博客
论文链接:[2303.13612] NOPE: Novel Object Pose Estimation from a Single Image (arxiv.org)
项目链接:NOPE: Novel Object Pose Estimation from a Single Image (nv-nguyen.github.io)
Abstract
由于需要3D模型的先验知识,且在面对新对象时,需要额外的训练时间,3D对象位姿估计的实用性在许多应用中仍然受到限制。为了解决这一限制,我们提出了一种方法,该方法将新对象的单个图像作为输入(在已知另一张图片的基础上),并在不事先了解对象的3D模型的情况下预测该对象在新图像中的相对位姿,并且不需要对新对象和类别进行训练。我们通过训练一个模型来直接预测物体周围视角的判别嵌入来实现这一点。这种预测是使用一个简单的U-Net架构来完成的,它的注意力和条件取决于期望的位姿,这产生了极快的推断。我们将我们的方法与最先进的方法进行比较,并表明它在准确性和鲁棒性方面都优于它们。我们的源代码可以在https://github.com/nv-nguyen/nope上公开获得。
1. Introduction
在过去十年中,物体的三维位姿估计在鲁棒性和准确性方面都取得了重大进展[12, 16, 33, 47, 57]。具体来说,对部分遮挡的鲁棒性已经有了相当大的提高[8, 29, 30],并且通过使用域转移[1]、域随机化[14, 44, 48]和利用合成图像进行训练的自监督学习技术[46],对大量真实带注释的训练图像的需求已经放松。
不幸的是,3D物体位姿估计的实用性在许多应用中仍然有限,包括机器人和增强现实。通常,现有的方法需要一个3D模型[15],一个视频序列[6, 43],或目标物体[58]的稀疏多幅图像(仅参考最近的作品),以及一个训练阶段。有几种技术旨在通过假设新对象属于已识别的类别[5, 51],与之前训练过的示例(如T-LESS数据集[44])有相似之处,或者表现出明显的角点[31],从而避免重新训练的需要。
在本文中,我们介绍了一种称为NOPE(Novel Object Pose Estimation)的新对象位姿估计方法,该方法只需要新对象的单个图像即可预测该对象在任何新图像中的相对位姿,而不需要对象的3D模型并且没有对新对象进行训练。这是一项非常具有挑战性的任务,因为与[43, 58]中使用的多个视图相比,单个视图仅提供有关对象几何形状的有限信息。
为了实现这一目标,我们训练NOPE来生成物体的新视图。这些新视图可以看作带有相应位姿注释的“模板”。将这些模板与新的输入视图相匹配,可以让我们估计物体相对于初始视图的相对位姿。我们的方法与新视图合成的最新发展有关。然而,我们更进一步:受最近用于位姿估计的模板匹配工作的良好性能[28, 40]的激励,我们不是预测纯色图像,而是直接预测视图的判别嵌入。具体来说,我们的嵌入是通过U-Net架构将输入图像传递给新视图,并以新视图的所需位姿为条件。
本质上,与现有的新视图合成工作[24, 32]相比,对于我们的位姿估计任务,我们不需要创建对象的3D模型。这节省了大量的计算时间,因为使用单视图优化3D模型至少需要一个小时[62]或更长时间。相比之下,我们基于视图嵌入的直接推理方法非常快,在不到2秒的时间内处理图像。并且,它对未见过的实例或类别产生准确的位姿估计,平均准确率超过65%。我们的工作也与两幅图像之间的运动预测有关,如[27, 49],它预测了两幅图像之间的相机位移。我们与[27]最接近的工作进行了比较,结果表明我们明显优于这种方法。
此外,我们表明,我们的方法在没有得到对象的3D模型,且只有一个单视图的情况下,可以识别位姿的模糊性,例如,对称[20]。
为此,我们估计查询的所有位姿的分布,随着位姿歧义越来越多,其峰值越来越少。图1描述了各种模糊和非模糊情况及其位姿分布:
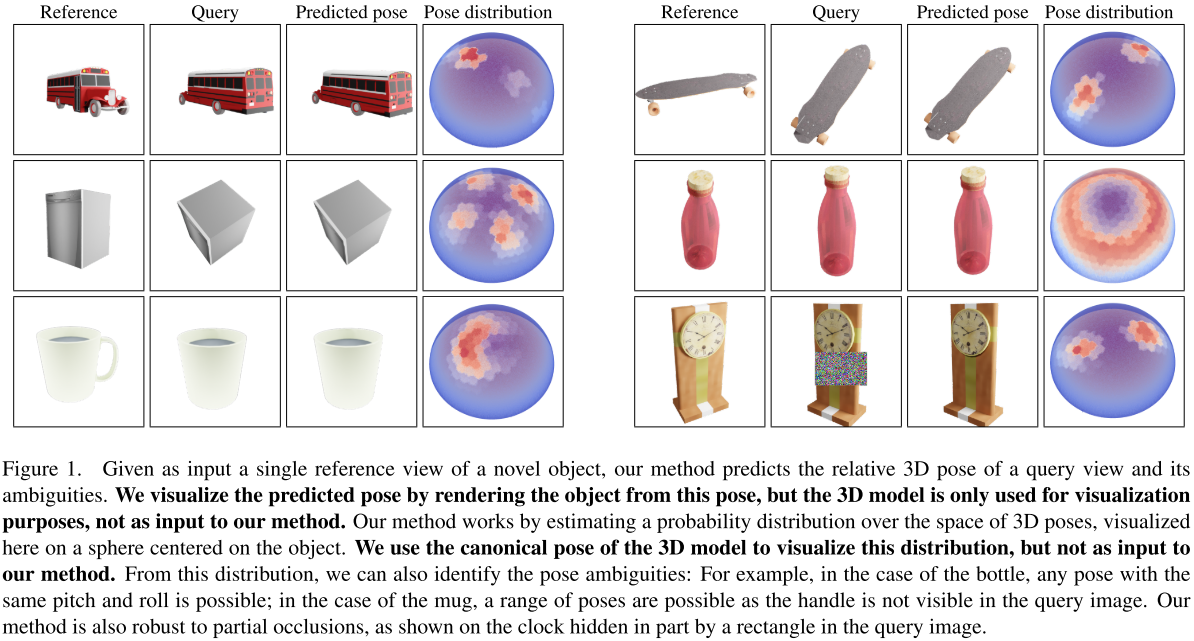
总之,我们的主要贡献是,在新视图中,且只给出该物体的单一视图的情况下,我们可以有效和可靠地恢复一个未见过的物体的相对位姿。据我们所知,我们的方法是第一个仅从单一视图预测由于对称性和不可见物体的部分遮挡而导致的模糊性的方法。
2. Related work
在本节中,我们首先回顾实现新视图合成的各种方法。然后,我们将注意力转移到旨在实现泛化的位姿估计技术上。
2.1. Novel view synthesis from a single image
我们的方法生成判别特征视图,该视图以参考视图和视图之间的相对位姿为条件。这与NeRFs[25]的开创性工作有关,因为它执行新视图合成。虽然最近的进展已经提高了NeRFs的速度[26, 39, 55],但我们的方法仍然要快几个数量级,因为它不需要创建完整的3D体积模型。此外,我们的方法只需要一个输入视图,而典型的NeRF设置需要大约50个视图。减少NeRF重建所需的视图数量仍然是一个活跃的研究领域,特别是在单视图场景中[24, 56]。
最近的研究[24, 62]通过利用二维扩散模型,利用稀疏视图集作为输入,通过NeRFs成功地生成了新的视图。对于图像,扩散模型的突破[7, 41]已经解锁了几个工作流程[35, 37, 38]。对于3D应用程序,DreamFusion[32]开创了分数蒸馏采样技术,允许使用2D扩散模型作为基于图像的损失,并通过可微分渲染在3D应用程序中进行利用。这使得以前使用基于CLIP的图像损失训练的任务得到了显著的改进[9, 10, 13, 17, 34, 50]。通过在分数蒸馏采样的基础上构建,在使用至少两个视图的基础上,SparseFusion[62]重构了一个NeRF场景,而同时期的一项工作RealFusion[24]从单个输入视图进行重构,尽管重构时间对于实时应用来说是不切实际的。我们的方法要快得多,因为我们不需要创建对象的3D表示。
与我们的工作最接近的是3DiM[52],这项工作通过在位姿上调节扩散模型来生成物体的新视图。他们没有像DreamFusion那样利用2D基础扩散模型,而是专门针对此任务重新训练扩散模型。虽然他们还没有将他们的方法应用到基于模板的位姿估计中,但我们设计了这样一个基线并与之进行比较。我们发现扩散模型总是倾向于生成清晰的图像,即使有时会改变纹理或产生错误的细节,这也会阻碍基于模板的方法的性能。相比之下,我们的方法直接在嵌入空间而不是像素空间中生成新的视图,正如我们将在3.1节中演示的那样,这要有效得多。
最后,几种方法[22, 23]通过调节3D位姿的前馈神经网络来生成新颖的视图,我们也使用U-Net来实现这一点。我们与这些方法在速度上有一个共同的优势:这种前馈神经网络比目前的扩散模型快一到两个数量级。然而,我们执行位姿估计的方式是完全不同的。我们在基于模板的匹配方法[28]中使用新视图合成,而他们在基于回归的优化中使用它。在实践中,我们发现这些方法在有限数量的对象类别上工作得很好,并且我们观察到它们在评估新类别时的性能显著下降。
2.2. Generalizable object pose estimation
尽管最近许多从图像中估计物体三维位姿的方法在效率和精度方面都取得了显着进步[2, 14, 30, 42, 44, 45, 53],但大多数方法只能适用于已知物体,这意味着它们需要在每个新物体上重新训练,从而限制了它们的应用范围。
人们已经探索了几种技术来更好地推广到未见过物体的位姿估计,例如通用2D-3D对应关系[31]、基于能量的策略[58]、关键点匹配[43]或模板匹配[15, 18, 28, 40, 59]。尽管取得了重大进展,但这些方法要么需要精确的目标三维模型,要么依赖于来自不同视角的多幅带注释的参考图像。这些3D注释在实践中很难获得。相比之下,我们提出了一种既不使用目标的3D模型也不使用多视图注释的策略。更重要的是,我们的方法只需要一个参考图像就能预测出准确的位姿,并且不需要再训练就能推广到新的对象。
3. Method
3.1. Motivation
为了激励我们的方法,我们评估了最先进的基于3D模型的图像生成方法(3DiM)[52]在位姿估计中的使用。3DiM是一种基于扩散的像素空间视图合成方法。为了将其应用于给定对象参考图像的位姿预测,我们尝试使用它从许多不同的视角生成一组新视图,并将对象的查询图像与这些视图在像素空间中进行匹配。由于生成的视图被标注了相应的位姿,这给了我们一个位姿估计。
如图2所示,3DiM生成的图像看起来非常逼真:
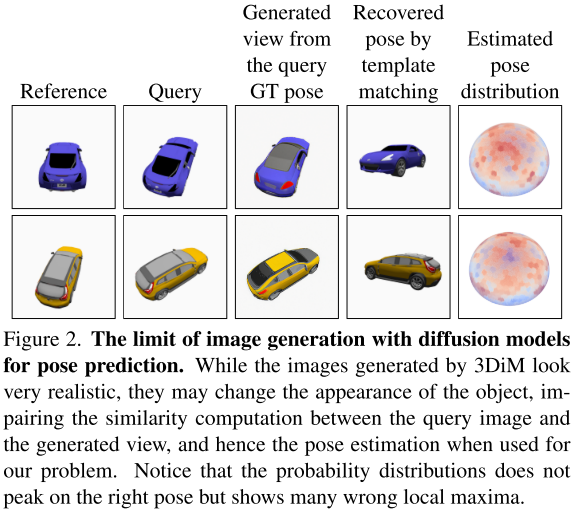
然而,恢复的位姿不是很准确。这可以部分解释为扩散可以“发明”干扰图像匹配的细节。这种方法的局限性将在我们的实验中得到进一步的实证证明(表1):
这促使我们学习直接生成视图的判别表示。
在本节中,我们首先用一个基于新视图生成的实验来激励我们的方法。然后我们描述我们的架构,我们如何训练它,以及我们如何使用它进行位姿预测和识别位姿歧义。
3.2. Framework
图3概述了我们的方法:
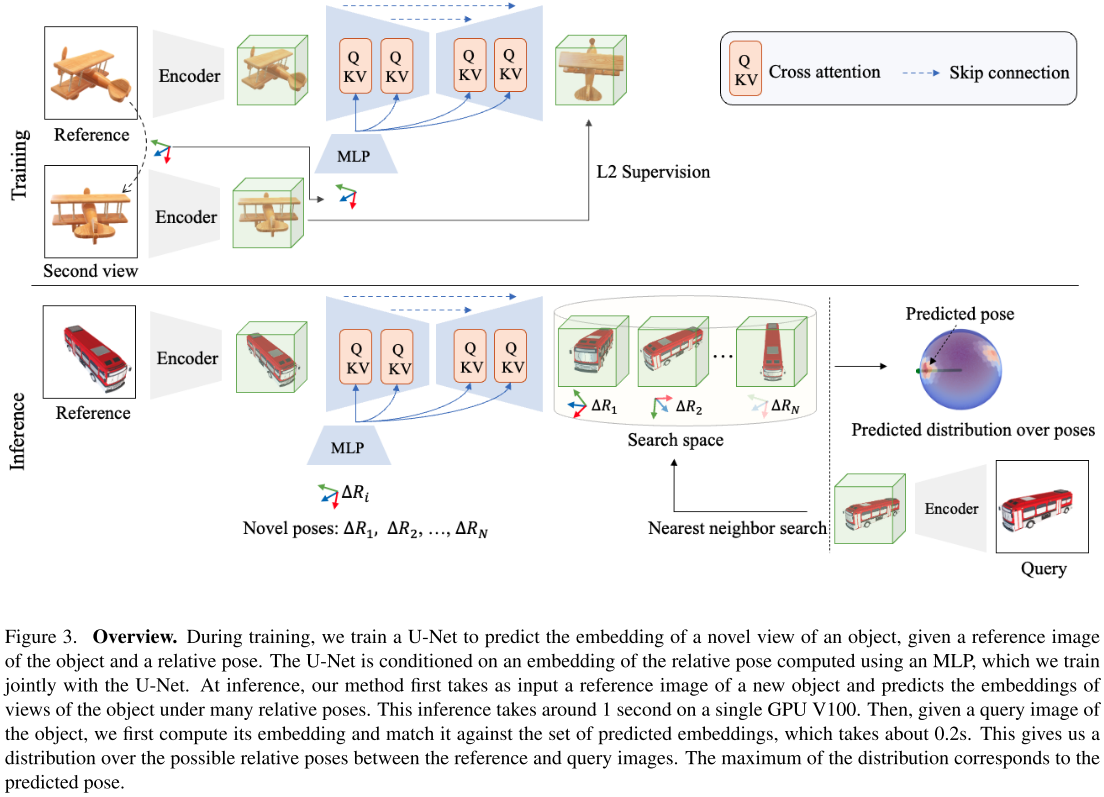
我们训练一个深度架构,使用第一组对象类别中的对象图像对来生成对象的新视图嵌入。在实践中,我们考虑用[28]的网络计算嵌入,因为它被证明可以产生模板匹配的鲁棒表示。为了生成这些嵌入,我们使用类似U-Net的网络,其位姿调节机制与3DiM[52]中引入的机制非常接近,并且与[36]中的文本到图像机制相关。
更准确地说,我们首先使用多层感知机(MLP)将参考视图中相对于物体位姿的期望相对位姿$\Delta R$转换为位姿嵌入。然后,我们使用交叉注意力将这个位姿嵌入到U-Net的每个阶段的特征图中,如[36]所述。
Training. 在每次训练迭代中,我们构建一个由$N$对图像组成的批,其中包括一个参考图像和具有已知相对位姿的同一物体的另一个图像。U-Net模型以参考图像的嵌入为输入,并以相对位姿的嵌入为条件来预测第二图像的嵌入。我们通过最小化预测嵌入与查询图像嵌入之间的欧氏距离来共同优化U-Net和MLP。注意,我们冻结了[28]计算嵌入的网络,因为它已经被训练过了。
通过在不同的对象数据集上进行训练,这种架构可以很好地推广到新的未知对象类别,正如我们的结果所示。
3.3. Pose prediction
Template matching. 一旦我们的架构得到训练,我们可以用它来生成新视图的嵌入:给定参考图像$\mathbf{I}_\mathrm{r}$和一组$N$个相对位姿$\mathcal{P} = (\Delta R_1, \Delta R_2, \cdots, \Delta R_N)$,我们可以得到一组相应的预测嵌入$(\mathbf{e}_1, \mathbf{e}_2, \cdots, \mathbf{e}_N)$。为了定义这些视角,我们遵循[28]中使用的方法:我们从一个正二十面体开始,将每个三角形递归地细分为四个较小的三角形两次,以获得342个最终视角。
最后,我们简单地执行最近邻搜索来确定嵌入最接近查询图像嵌入的参考点。请注意,这可以有效地完成[28]。
Detecting pose ambiguities. 当物体具有对称性时,或者当可以消除模糊性的物体部分不可见时,就会出现位姿模糊性,如图1中的马克杯。通过考虑查询图像的嵌入与生成的嵌入之间的距离,我们不仅可以预测单个位姿,还可以识别给定参考视图和查询视图的所有其他可能的位姿。
更正式地,我们估计给定参考图像$I_r$和查询图像$I_q$的相对位姿$\Delta R$的概率为:
其中$\mathbf{e}_{\Delta R}$为U-Net根据参考图像$I_r$和相对位姿$\Delta R$预测的嵌入,$\mathbf{e}_q$为查询图像$I_q$的嵌入,$Z$为归一化因子。算子$\cdot$表示点积。
为了说明这一点,我们在图4中展示了三种不同类型的对称:
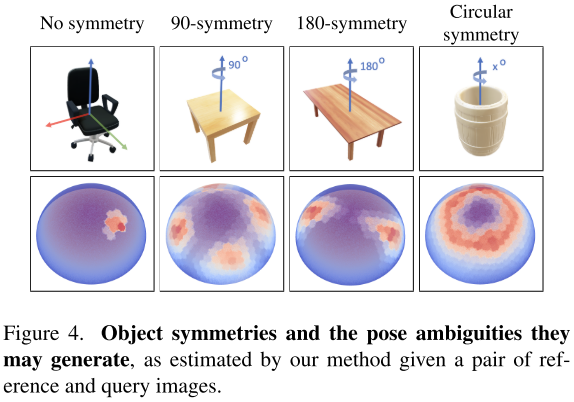
并可视化了相应的参考和查询图像对的位姿分布(未显示)。相似度得分高的区域数量与对称和构成歧义的数量是一致的:如果一个物体没有对称,则概率分布有一个明确的模式。对称物体的概率分布在旋转对称的情况下通常具有几个模态,甚至是一个连续的高概率区域。我们在第4节中提供了额外的定性结果。
4. Experiments
在本节中,我们首先在4.1节中描述我们的实验设置,然后在4.2节中将我们的方法与其他方法[21, 22, 27, 52]在可见和不可见对象类别上进行比较。第4.3节报告了对部分遮挡的鲁棒性的评估。在第4.4节中,我们进行了消融实验,以研究我们的方法在不同环境下的有效性,最后在第4.6节中讨论了我们的方法的失败案例。
4.1. Experimental setup
Dataset. 据我们所知,我们是第一个解决当对象属于训练期间未见的类别时,从单个图像中估计对象位姿问题的方法:PIZZA[27]在DeepIM改进基准上进行评估,该基准由具有较小相对位姿的图像对组成;SSVE[22]和ViewNet[21]仅对训练期间看到的类别中的对象进行评估。
因此,我们必须创建一个新的基准来评估我们的方法。我们使用ShapeNet[3]中与FORGE[11]中相同的对象类别创建了一个数据集。对于训练集,我们从FORGE中所做的13个类别(飞机、长凳、橱柜、汽车、椅子、显示器、灯、扬声器、步枪、沙发、桌子、电话和船只)中的每个类别中随机选择1000个对象实例,结果总共有13,000个实例。我们构建两个独立的测试集进行评估。第一个测试集是“新实例”集,它包含50个新实例,这些实例在训练期间没有出现,但仍然来自用于训练的对象类别。第二个测试集是“新类别”集,包括从FORGE选出的10个未见过的类别(公共汽车,吉他,时钟,瓶子,火车,杯子,洗衣机,滑板,洗碗机和手枪)中选出的100个模型。对于每个3D模型,我们随机选择相机位姿生成五张参考图像和五张查询图像。我们使用BlenderProc[4]作为合成渲染引擎。
图5说明了用于训练我们架构的类别和用于测试它的类别:
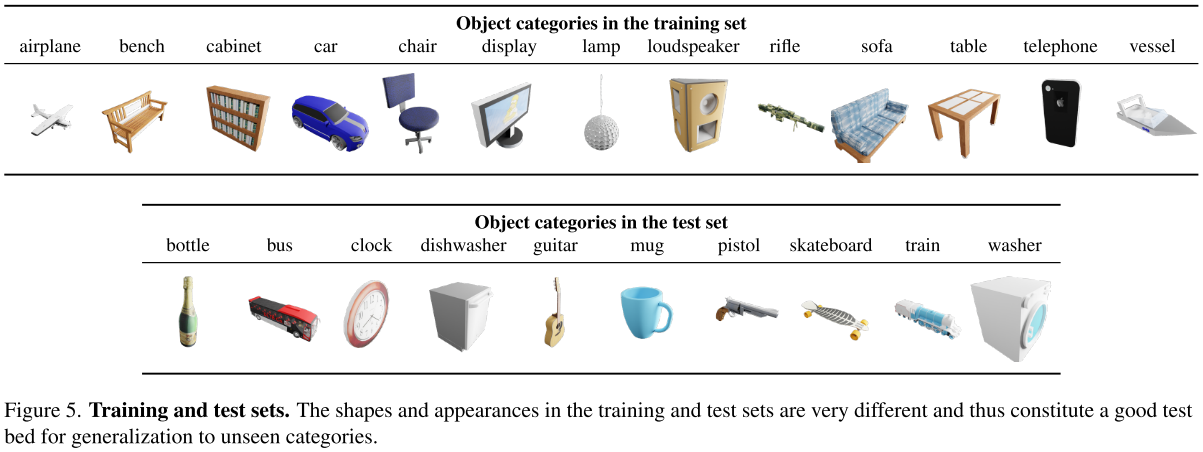
测试集中类别的形状和外观与训练集中类别的形状和外观有很大的不同,因此构成了一个很好的测试集,可以泛化到未见过的类别。
Metrics. 我们根据相对相机位姿误差报告了两个不同的指标,如[22]中所做的那样。具体来说,我们为测试集中的每个类别提供了跨实例的中位数位姿误差,以及当位姿误差$\le 30^\circ$时预测被视为正确的精度Acc 30。此外,我们给出了我们的方法对模板匹配检索到的前3和5个最近邻的结果。
Baselines. 我们将我们的工作与之前所有旨在从单一视图预测位姿的方法(据我们所知)进行比较:PIZZA[27]是一种直接预测相对位姿的基于回归的方法,SSVE[22]和ViewNet[21]采用半监督和自监督技术,将视角估计视为使用条件生成的图像重建问题。
我们还将我们的方法与最近基于扩散的方法3DiM[52]进行了比较,后者生成像素级视图合成。由于3DiM最初只针对视图合成,而不是为3D对象位姿设计的,我们使用它来生成模板并执行最近邻搜索来估计3D对象位姿,如3.1节所述。为了使3DiM在与我们相同的环境中工作,我们重新训练它相对位姿条件调节而不是规范位姿条件调节。
只有PIZZA的代码可用。在撰写本文时,其他方法没有发布它们的代码,但是我们重新实现了它们。我们对“新实例”情况的数值结果与相应论文中报告的结果相似,这验证了我们的实现。我们使用[27]中的ResNet18主干网络来处理PIZZA、SSVE和ViewNet。
我们在分辨率为$256 \times 256$的输入图像上训练所有模型,但3DiM除外,我们使用$128 \times 128$的分辨率,因为3DiM在像素空间中执行视图合成,这需要更多的内存。我们的重新实现在对相同的数据进行评估时获得了与原始论文相似的性能,如表1所示:
它验证了我们的重新实现。我们的方法还使用[28]中的冻结编码器将输入图像编码为大小为$32 \times 32 \times 8$的嵌入。对于所有的方法,我们使用AdamW[19],初始学习率为1e-4。每种方法平均需要在4GPU V100上进行10小时的训练。我们建议读者参阅补充材料以了解更多实现细节。
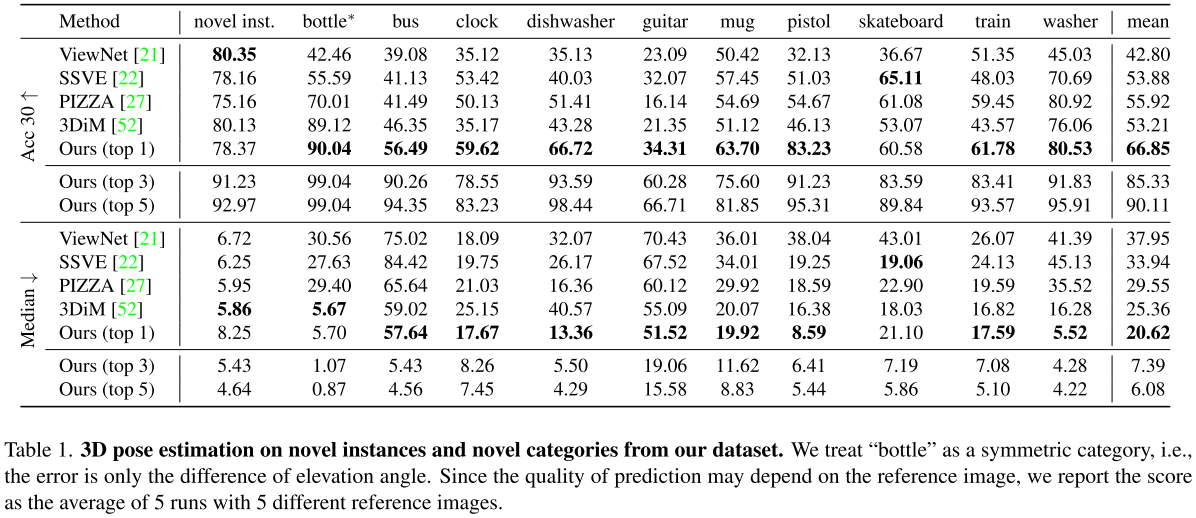
4.2. Comparison with the state of the art
表1总结了我们的方法与上述基线的比较结果。在Acc30和Median指标下,我们的方法始终达到最佳的整体性能,在Acc30和Median指标上的表现分别超过基线的10%和10%。特别是,虽然其他工作能在未见过的训练类别中的实例上产生合理的结果,但他们经常难以从未见过的类别中估计物体的3D位姿。相比之下,我们的方法在这种情况下效果很好,在未见过的类别上表现出更好的泛化能力。
图6显示了我们的方法在有对称性和没有对称性的未见类别上的一些可视化结果:
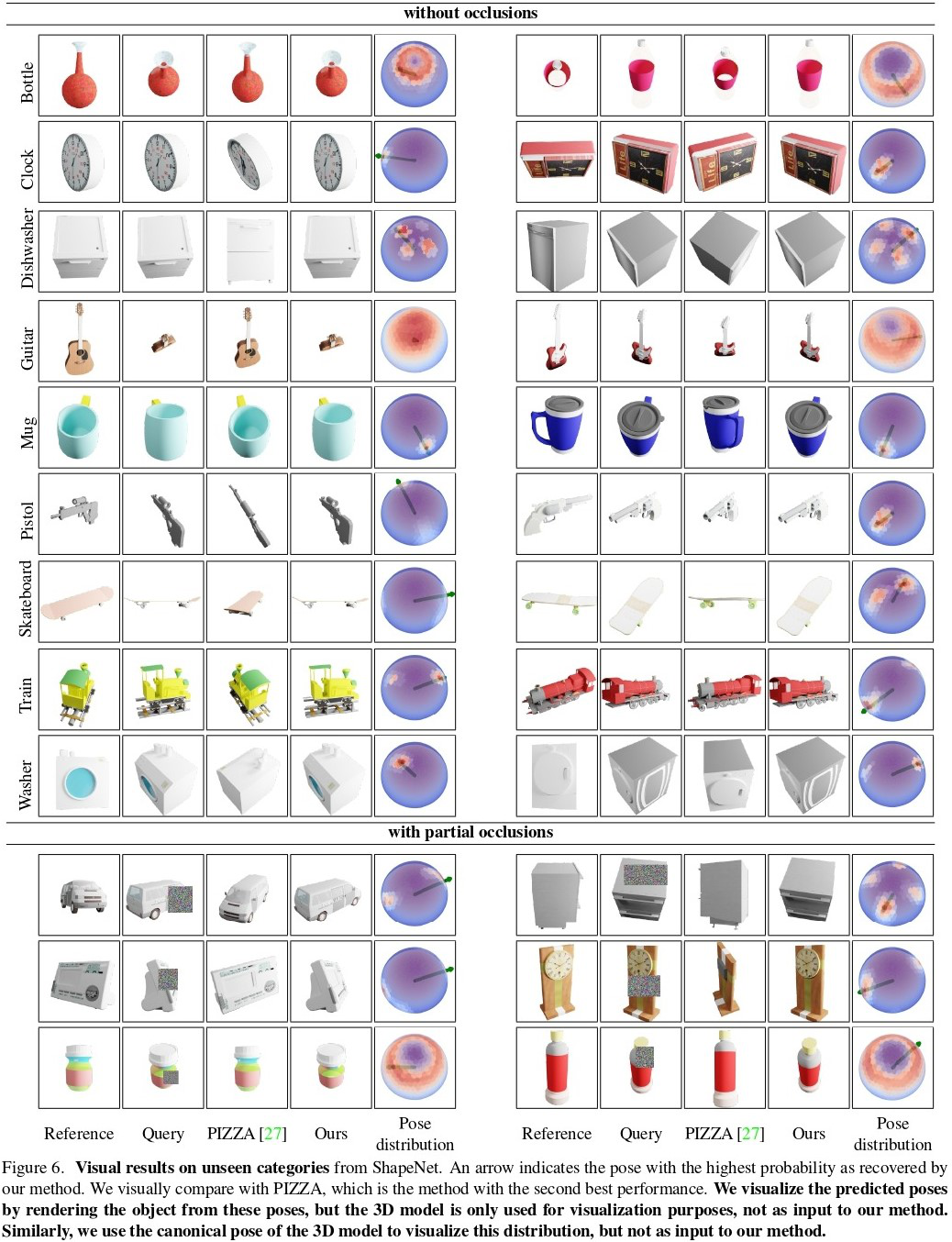
当存在对称轴时,我们的方法比基线产生更精确的3D位姿。
4.3. Robustness to occlusions
为了评估我们的方法对遮挡的鲁棒性,我们在对象上的查询图像中添加了填充高斯噪声的随机矩形,以类似于随机擦除[60]的方式。我们改变矩形的大小,以覆盖对象bounding box的0%到25%的范围。图1和图6显示了几个示例。
表2比较了我们之前评估中表现最好的第二种方法PIZZA与我们的方法在不同遮挡率下的性能:
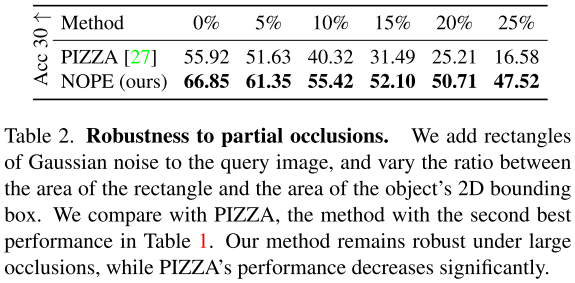
我们的方法即使在大遮挡下也保持鲁棒性,这要归功于用于匹配图像的鲁棒性判别嵌入。
在图6中,请注意我们的位姿概率保持在正确的最大值上,并且当它们存在时仍然显示出清晰的对称性。
4.4. Ablation study
Pose conditioning. 我们尝试了两种不同的位姿表示。3DiM首先从给定的3D位姿创建相机光线,并使用[25]的位置编码来获得逐像素的位姿条件。在我们的方法中,该表示在集成到U-Net的特征图之前,由MLP处理。我们对这种方法进行了实验,但发现与直接对旋转表示应用MLP相比,它并没有提高我们问题的性能。我们喜欢第二种方法,因为它简单。
Rotation representation for the relative pose. 同样,我们尝试了不同的旋转表示:轴角、四元数和旋转-6D[61]。我们观察到所有这些表示都会产生类似的性能,因此我们在所有实验中都使用旋转-6D[61]。
4.5. Runtime analysis
我们在表3中报告了NOPE和3DiM的运行时间:

我们的方法比3DiM要快得多,这要归功于我们的策略是用一个步骤而不是多个扩散步骤来预测新视点的嵌入。
4.6. Failure cases
当对“公共汽车”和“吉他”类别进行评估时,所有方法都不能产生准确的结果,正如高中位数误差所表明的那样。经过目视检查(参见图7):

似乎吉他类别的3D模型在某些视点下可能非常薄。此外,吉他和巴士类别都是“几乎对称的”,在某种意义上,只有小细节才能使位姿不模棱两可。
为了检查这是否真的是这两个类别表现不佳的原因,我们重新运行评估,将“吉他”类别的参考视图作为具有最大轮廓的视图,并将这两个类别视为具有180度对称。表4给出了这项新评价的结果:
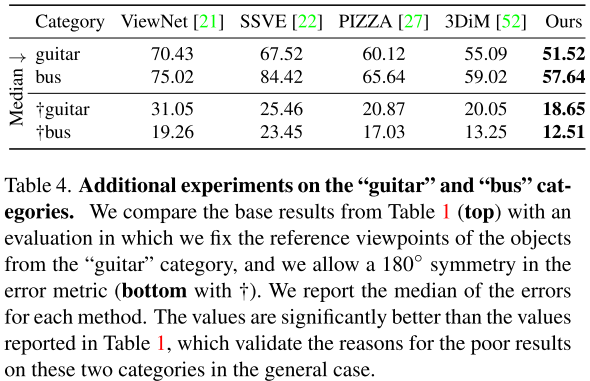
度量标准明显更好。这表明,失败确实是由物体看起来非常薄的视图和“准对称性”引起的。
5. Conclusion
我们提出了NOPE,一种从单个图像中估计新物体位姿的方法。我们的实验表明,从单个视图中直接推断视图嵌入可以准确地估计物体位姿,甚至对于来自未知类别的物体,同时既不需要重新训练也不需要3D模型。此外,我们已经证明,我们遵循的模板匹配方法可以让我们估计许多对象出现的位姿歧义。
















